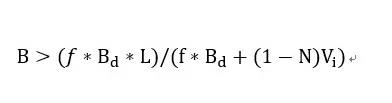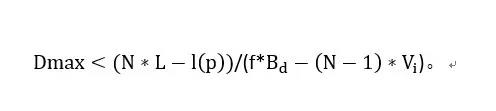基于FAST的TSN交换(5)TSN交换机队列结构和延时分析
发布时间:2019-1-22
交换机中的排队延时是给分组端到端延时带来不确定性的重要因素。由于要支持确定性的延时,TSN交换机中的队列设计必须有别于传统的标准交换机。基于FAST流水线扩展模型和CQF-UDO模块设计,我们在openbox-S4可编程平台上展开TSN交换机原型(FAST-TSN-04)设计,本文详细介绍了该原型机中的队列模型,并对分组交换延时进行分析。
一、FAST-TSN-04的队列模型
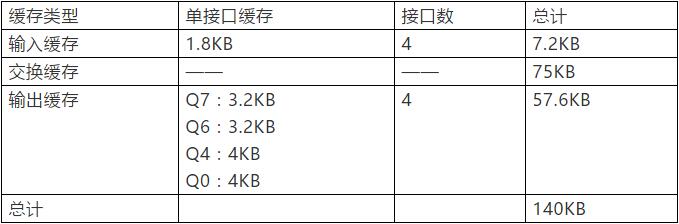
FAST-TSN-04基于Openbox-S4实现(核心FPGA为ZynqXC7Z030),支持4个千兆以太网接口分组和TSN的CQF流量整形,可保证精确的分组交换延时。其内部的队列结构如下图所示。分组交换过程的缓存主要分为三个阶段,即输入缓存,交换缓存和输出缓存。
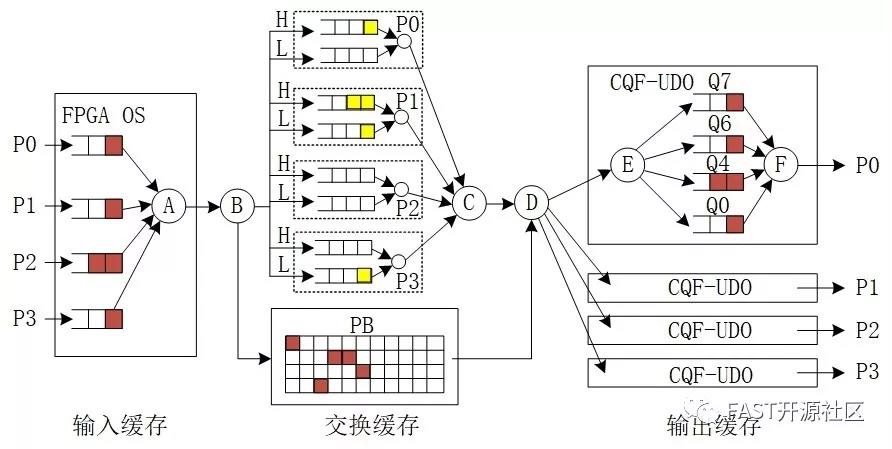
图1 FAST-TSN-04的缓存结构
(1)输出缓存
输入缓存在openbox-S4平台提供的FPGA OS中实现,用户无法根据TSN的转发需求进行任何修改和定制。每个接口接收的分组不加区别的按照先来先服务的队列形式保存在输入缓存FIFO队列中。FIFO队列的宽度为128bit,时钟频率为125HHz。由于每个接口速率为1Gbps,因此进入FIFO队列的速率最大为1Gbps,而在A点调度器调度分组输出带宽为16Gbps(128b*125MHz)。
参考文献[1]证明了在上述队列结构下,每个FIFO队列不溢出的条件为:
且分组在队列中的最大延时:
将Vi=1Gbps,f=125MHz,Bd=128b,L=1500B,N=4带入可得将每个接收的FIFO队列长度设置为1.8KB即可保证无分组溢出,分组的最大延时为4.5us。
(2)交换缓存
交换缓存采用共享存储方式,即B点(FAST流水线中的GPP模块)从PB获取空闲的缓冲区块地址,将每个到达的分组写入PB中存储,同时将地址信息写入分组的元数据中。FAST流水线模块(GKE、GME、GAC)利用分组的元数据进行交换查表,得到其目的输出接口,即可将分组的元数据(包含分组优先级和输出接口号)写入相应的输出队列中等待调度。
GAC没有对TSN进行优化设计,每个端口仅支持高(H)低(L)两个优先级队列。支持TSN时,可配置将优先级4-7的分组元数据送高优先级队列缓存,优先级0-3的分组元数据送低优先级队列缓存。C点(GAC模块)的调度器采用两级调度的思想,第一级是每个输出端口调度高优先级分组输出,第二级是在多个优先级队列中采用Round-Robin方式进行调度。
采用RR调度可能导致一个端口的低优先级帧先于另一个端口的高优先级队列发送,这种情况是合理的,因为GAC调度对应的速率为16Gbps,而对应CQF-UDO的输出带宽为1Gbps,即使高优先级帧被优先调度到UDO模块,还需要在UDO模块中进行进一步缓存。
交换缓存是交换机中的重要缓存。当多个输入端口向一个输出端口同时发送数据时,交换机理想的缓存应该在一定流量条件下保证输出接口不溢出。目前TSN工作组正在制定面向工业自动化场景的TSN规范草案“IEC/IEEE 60802 TSN Profile for Industrial Automation“,在工作组最新文档(参考文献2)中给出了交换机输出接口缓存资源MinimumFrameMemory的计算公式:
MinimumFrameMemory= (NumberOfPorts – 1) × MaxPortBlockingTime × Linkspeed
其中NumberOfPorts为交换机接口数,MaxPortBlockingTime为数据缓存时间,Linkspeed为接口链路速率。通过上述公式,文档给出了当接口数目为4,链路速率为1Gbps,MaxPortBlockingTime为典型值200us时,需要的缓存大小为75KB。
(3)输出缓存
输出缓存位于CQF-UDO内部,是针对TSN CQF流量整形机制设计的专用队列。CQF-UDO包含4个队列,其中Q7和Q6为保存时间敏感分组的乒乓队列,Q4为保存带宽预约分组的队列,Q0为保留Best Effort分组的低优先级队列。
由于时间敏感分组(优先级为7)和预约带宽分组(优先级为4)在交换缓存中作为高优先级分组会被优先调度到UDO,因此对于合理的离线调度(不会造成输出端口拥塞),高优先级流量不会在输出端口长时间排队。
造成输出接口Q7/Q6排队的是CQF模型。假设时间敏感流量乒乓队列切换的时间槽为125us(802.1Qch中给出的典型切换时间),且时间敏感流量不超过链路负载的20%(200Mbps),因此Q7和Q6每个队列缓存最大需要125us*20%*1Gbps,即3.2KB。
Q4队列主要保存带宽预约流量,由于在D点(GOE)可使用令牌桶对流量整形,因此Q4的长度只等于令牌桶的桶深即可,这里可设置为4KB。
Q0队列只是用于16G速率到接口1Gbps速率的转换,只要D点(GOE)对UDO进行正体1Gbps的带宽限速,Q0队列只需缓存一个大的完整分组即可,因此选择2KB即可。
二、缓存资源和转发延时评估
(1)存储资源评估
根据以上分析,对FAST-TSN-04使用的存储资源进行评估如下表所示。
Opnebox-S4选用Zynq芯片XC7Z030内嵌的缓冲区为9.3Mb,而FAST-TSN-04使用的缓冲区大小为140KB,约1.1Mb。因此即使考虑数据成块分配导致缓存效率降低, FPGA内部缓存是可以满足需求的。
(2)延时评估
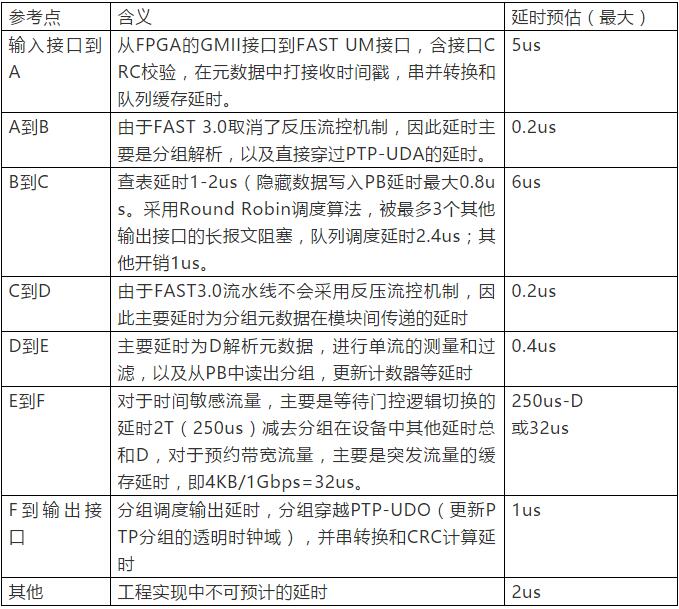
对FAST-TSN-04的延时评估主要针对时间敏感流量和带宽预约流量。基于上述分析,图中各参考点之间的延时估算如下表所示。表中的延时估算为头进到头出的延时。对于最大分为1500B和千兆带宽,分组头进尾出延时还要增肌1500*8b/1GBps=12us左右。由于FAST流水线时钟为125MHz,每个时钟节拍8ns,1us约125个时钟节拍。
基于上述分析,不考虑CQF的缓存需求,交换流程中高优先级分组(时间敏感分组和预约带宽分组)最大延时约15us。对于无离线规划的best effort分组,最大延时可能超过600us(75KB/1Gbps)。
参考文献
[1] 李韬,孙志刚等,面向下一代互联网实验平台的新型报文处理模型——EasySwitch, 计算机学报,2011年11期
[2] Use CasesIEC/IEEE 60802 V1.3,https://1.ieee802.org/tsn/iec-ieee-60802-tsn-profile-for-industrial-automation/